Boosting vs Bagging Model Improvement Techniques
In machine learning, there are two popular techniques for improving the accuracy of models: boosting and bagging. Both techniques are used to reduce the variance of a model, which is the tendency to overfit to the training data. While they have similar goals, they differ in their approach and functionality. In this article, we’ll explore the differences between boosting and bagging to help you decide which technique is right for your machine learning project.
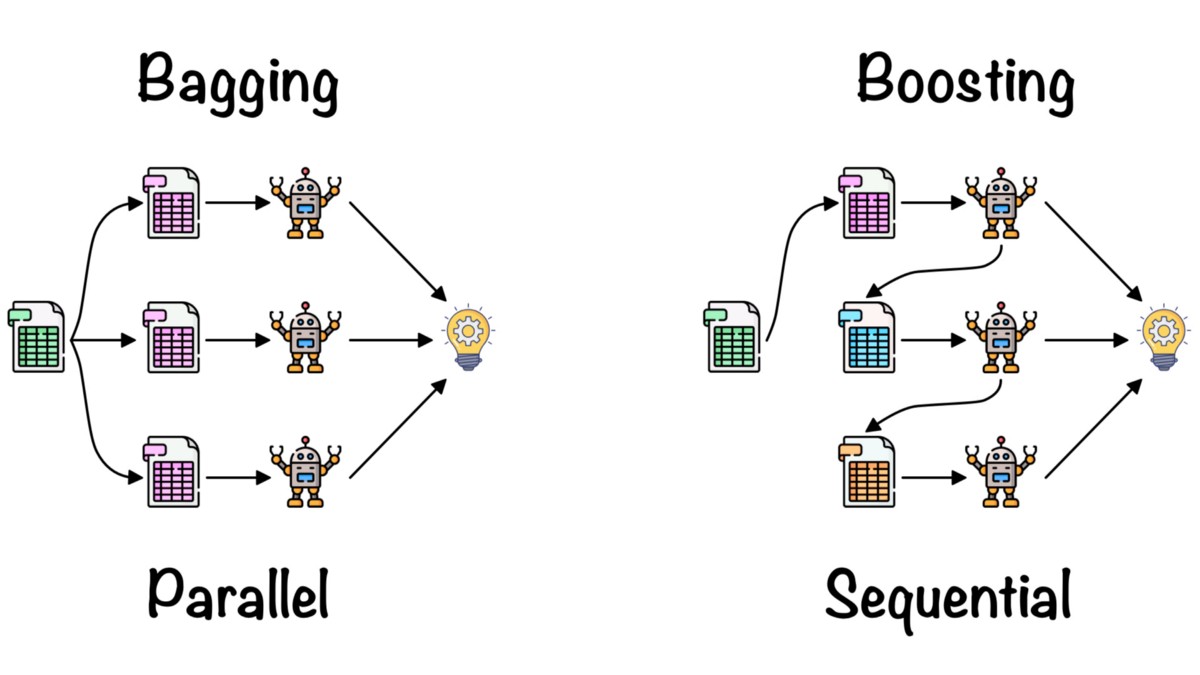
Bagging:
Bagging, short for bootstrap aggregating, is a technique that involves training multiple models on different random subsets of the training data. The goal of bagging is to reduce the variance of a model by averaging the predictions of multiple models. Each model in the ensemble is trained independently and the final prediction is the average of all models. Bagging can be used with any algorithm, but it is most commonly used with decision trees. The most popular implementation of bagging is the random forest algorithm, which uses an ensemble of decision trees to make predictions.
Boosting:
Boosting is a technique that involves training multiple weak models on the same training data sequentially. The goal of boosting is to improve the accuracy of a model by adding new models that focus on the misclassified samples of the previous model. Each model in the ensemble is trained on the same dataset, but with different weights assigned to each sample. The weights are adjusted based on the misclassified samples of the previous model. The final prediction is a weighted average of all models in the ensemble. Boosting is commonly used with decision trees, but it can be used with any algorithm.
Differences between Boosting and Bagging:
While boosting and bagging have similar goals, they differ in their approach and functionality. The main differences between these two techniques are:
- Approach: Bagging involves training multiple models independently on different random subsets of the training data, while boosting trains multiple models sequentially on the same dataset with different weights assigned to each sample.
- Sample Weighting: Bagging assigns equal weight to each sample in the training data, while boosting assigns higher weight to misclassified samples.
- Model Selection: In bagging, the final prediction is the average of all models in the ensemble, while in boosting, the final prediction is a weighted average of all models in the ensemble.
- Performance: Bagging can reduce the variance of a model and improve its stability, but it may not improve its accuracy. Boosting can improve the accuracy of a model, but it may increase its variance and overfitting.
Conclusion:
In conclusion, boosting and bagging are two popular techniques for improving the accuracy of machine learning models. While they have similar goals, they differ in their approach and functionality. Bagging involves training multiple models independently on different subsets of the training data, while boosting trains multiple models sequentially on the same dataset with different weights assigned to each sample. Which technique is right for your machine learning project depends on your specific needs and goals. Bagging can improve model stability, while boosting can improve model accuracy.
Comments welcome!